AE Analytics
General Climate Profiles Guidance
Overview
Many energy system modeling and other planning processes are designed to intake hourly information to capture short term fluctuations in conditions that affect power supply and demand (NYSERDA 2020; Smith et al. 2025). An annualized hourly climate profile is a dataset that contains hourly weather conditions at a given location for an entire year. Because it represents every hour of a 1-year period, a climate profile is also commonly referred to as an “8760” (the number of hours in one year). Although climate profiles have previously been generated using historical observation-based datasets, planners are increasingly interested in using annualized climate profiles that are constructed with future climate data. Annualized hourly climate profiles are able to represent future weather conditions due to a changing climate and can thus better inform design and planning processes for a wide range of future needs.
There are multiple kinds of climate profiles, including:
- Synthetically generated climate profiles, in which the climate profile is not selected from a single continuous model year; rather, each component (e.g., hour or month) is selected across the statistical distribution and then concatenated together to build a full year profile.
- Actual or realistic climate profiles, in which a single continuous year of either historical or future weather conditions is used as a representative of annual hourly conditions..
The Cal-Adapt: Analytics Engine currently provides two kinds of synthetic climate profiles:
- Standard Year 8760: One year of hourly data that represents any desired statistical percentile of weather conditions for a location over a 30-year climatological period. A Standard Year builds a climate profile for each climate model on a single variable and can be used to evaluate either median or extreme conditions by selecting appropriate percentiles. Both historical and future Standard Year 8760s are available.
- Typical Meteorological Year 8760 (TMY): One year of hourly data that represents the median weather conditions for a location over a climatological period. A TMY file is built from ten specific weather variables that are weighted in compliance with international standards (Wilcox and Marion 2008). TMY files statistically assess the median conditions from 30 years of model data and select the most “typical” month for each month during a year. The resulting TMY file includes multiple variables and has very specific formatting requirements. Both historical and future TMY (FTMY) 8760s are available.
Coming onto the Analytics Engine in 2026!
- Extreme 8760s: One year of hourly data that represents extreme weather conditions for a location over a climatological period. These profiles will include extreme TMYs (XMY), Stress Test 8760s, and other kinds of extreme climate profiles.
Accessing the data
Climate Profiles are accessible on the Cal-Adapt: Analytics Engine in two locations:
- An extensive set of pre-generated Standard Years and FTMYs are available in the Cal-Adapt: Data Catalog. The pre-generated Standard Year 8760s and FTMYs are available for four common energy sector planning horizons: present-day (1.2°C GWL), near-future (1.5°C GWL), mid-century (2.0°C GWL), and mid-late-century (2.5°C). For more information on global warming levels (GWL), see our guidance here.
- To generate a custom climate profile, including a custom GWL-based or time-based FTMY, check out the
custom_climate_profiles notebook, available on the Analytics Engine JupyterHub. Standard Year 8760s are not available via a time-based approach.
Standard Year 8760s
Methodology
A Standard Year is one year of hourly data that represents a statistical percentile of meteorological conditions for a location over a set amount of time (30 years). For example, for each hour of the year, the 90th percentile is taken across the same hour of the year from each of the 30 years of data. A Standard Year can be generated for any climate variable (temperature, solar radiation, etc.), any desired percentile (median and extremes), and for any location of interest. On AE, Standard Years can be generated for gridded areas and point locations across WECC. The Standard Year profile is built by selecting the real simulation value closest to the selected percentile for each hour of the year. The Standard Year profile is a synthetic profile, and thus differs from using a single continuous year of climate model data. Functionality to generate a “delta Standard Year” is also provided, in which a difference between the timeframe of interest and the historical reference period is returned. This can be used to evaluate climate change impacts on energy systems over time (see our guidance on Reference Periods).
Step 1: User selects desired information.
A user will first select four primary settings, with additional options:
- The variable of interest to build the Standard Year. A user can optionally select alternative units, if so desired.
- The percentile of interest, at which the variable is evaluated against the statistical distribution. The default percentile is the 50th percentile.
- The location of interest, including both gridded areas (e.g., county, service territory) and point-locations (e.g., weather station, utility asset).
- The timeframe of interest. On AE, Standard Years are currently calculated using global warming levels. A user can generate a Standard Year with any desired warming level, including custom levels (e.g., 1.37°C). A user can also optionally elect to calculate a delta Standard Year or an absolute Standard Year. An absolute Standard Year represents the values at the designated warming level, while a delta Standard Year calculates the difference between the selected warming level and a 1.2°C historical reference warming level.
Step 2: Compute distribution and select candidate hour for each hour.
At this stage, the data corresponding to the user selections (Step 1) are retrieved, and the statistical distribution is computed. The closest value from the distribution of simulation values at a given hour is then identified and returned for each hour of the year. This process is repeated for all 8 available dynamically-downscaled models on AE, including the 4 bias-adjusted models. The bias-adjusted and non-bias adjusted models are not collectively evaluated on the same distribution. Rather, the distribution is developed per model, and a separate profile for each model is returned. If a delta Standard Year is requested, the process is repeated for the selected warming level and the historical reference warming level (1.2°C) and the difference calculated for each model.
Step 3: Generate the Standard Year 8760 file.
Once each representative hour is selected, each model’s climate profile information is compiled into a single Standard Year file, with clear designations for each model’s profile. Standard Year files are provided in .csv format for ease of use. On the AE Jupyter Hub, an absolute Standard Year for a point location takes approximately 5 minutes to generate, and 20 minutes for a gridded area (based on LA County).
Note: a Standard Year can be generated for all of California, but it will take over an hour to complete.
Applications
After generating Standard Year files, users may ask what steps to take next. When generating Standard Year files on the AE, the AE intentionally returns a separate climate profile for each model, all contained within one Standard Year file. No further aggregation or downsampling is performed, as the appropriate approach depends on the user’s specific application and need for the Standard Year information. The following guidance is provided to support next steps in using these data.
When to evaluate the range of results
The differences between profiles from each climate model represents a sample of uncertainty from model differences and the natural variability of the climate. Examining these differences can provide valuable information about the possible range of future climate conditions. When an application requires understanding a range of future climate impacts using climate profiles, it is recommended to generate profiles at multiple percentiles for comparison. From there, users should evaluate the differences between models to determine how they inform the analysis. At this stage, users may elect to aggregate the model climate profiles within the Standard Year file and conduct an uncertainty analysis across the results.
When to aggregate results
If an application requires a single climate profile, users may elect to aggregate results across climate models. It is recommended to first evaluate climate profiles from all of the available models to understand the spread of results and how that may affect the aggregated result.
- Multi-model median: Computing a multi-model median across all model climate profiles is recommended when the application is sensitive to outliers or extreme values within the model range.
- Multi-model mean: Computing a multi-model mean across all model climate profiles is recommended when the application is not sensitive to outliers or extreme values within the model range.
- Multi-model range: Consider calculating the multi-model difference for each hour between the “max” and “min” model spread of conditions as a measure of uncertainty in addition to the multi-model aggregation.
When to select a single model
If an aggregated Standard Year (e.g., multi-model median) is not appropriate or desired (e.g. when it is necessary to retain a single model’s synthetic record rather than aggregate), users may elect to pick a climate profile from a particular model. It is recommended to first evaluate all of the available models to understand where each falls in the spread of “median” conditions. Additionally, it is strongly recommended to document which model was selected and why.
- Based on whether the application is sensitive to outliers and extreme values, select either the median model (application is sensitive) or the most average model (application is not sensitive).
- If the range between models is very small, or not critical for the application or location, any model can serve as a representation of the ensemble.
When to weight results
Weighting may be appropriate when an application involves multiple locations in the analysis of Standard Year data. Weighting options can include:
- Population weighting – for building capacity, or in comparison across different locations
- Location-based weighting – if your area of interest falls between several different weather stations
- Load weighting – for generation and demand forecasting capacity across a service territory
- Building design weighting – for comparison amongst different building types (e.g., commercial vs. residential)
- Weighting amongst different variables for a given location (e.g., temperature, humidity)
Typical Meteorological Year 8760s
Methodology
A TMY profile is one year of hourly data that represents the median meteorological conditions for a point location over a set amount of time (at least 15 years required). AE recommends and utilizes a 30-year period for TMY calculation, which adheres to compliance with global warming level calculations. A TMY profile is built from ten specific weather variables that are weighted based on TMY standards (NSRDB, Wilcox and Marion 2008). TMYs statistically assess the median conditions for those variables and select the most “typical” month for each month during a year. These are compiled into a single climate profile. For example, the most “typical” January within the 30 year period could be from 2010, while the most “typical” February could be from 2022, and so on. The end result is an hourly climate profile for an entire year with each month spliced together from multiple input years. TMY profiles are widely used as critical inputs for energy modeling, simulating solar energy conversion systems, and evaluating building standards and energy efficiency (NSRDB, Wilcox and Marion 2008; Laxo 2023).
Note: The TMY method and weighting schema in the Analytics Engine mirrors the NREL TMY version 3 method (NSRDB, Wilcox and Marion 2008).
Step 1: User selects location of interest and timeframe of interest (Historical TMY or Future TMY).
Calculating a historical or future TMY on AE is for point-based information, meaning that a user will first select a specific location of interest (e.g., a power plant or an airport weather station). At this point, the user will also select a period of time, such as a historical or future TMY (FTMY). On the AE, at least 15 years of daily data is required; the AE uses a default 30-year period. On AE, TMYs can be generated either via global warming level or time-based periods.
Step 2: Data is retrieved.
The input data for determining a “typical” month is retrieved for that location, which includes the following variables:
- Mean air temperature
- Min air temperature
- Max air temperature
- Mean dew point temperature
- Min dew point temperature
- Max dew point temperature
- Mean wind speed
- Max wind speed
- Global irradiance
- Direct irradiance
It is important to note that only the 4 bias-adjusted WRF downscaled models have all of the required variables to calculate a TMY profile – in particular, the two solar variables. The AE thus subsets the data to only include the relevant models. The last step in the data retrieval process is to ensure that all of the input data is in the local time zone for the location of interest. Because the input data is in UTC, the minimum temperature in hourly data “appears” on the day before (i.e., midnight on Monday in UTC corresponds to 5pm PST on Sunday). Converting to the local timezone is important to ensure that the daily minimum occurs on the correct day.
Step 3: Calculate the long-term climatological distribution.
The TMY method specifically uses a cumulative distribution function (CDF), which calculates the 30-year climatological distribution for each variable. This distribution is used as a baseline to determine which specific month within the 30-year period is closest to this baseline condition, and is repeated for all months (i.e., climatologically typical January, climatologically typical February, etc.).
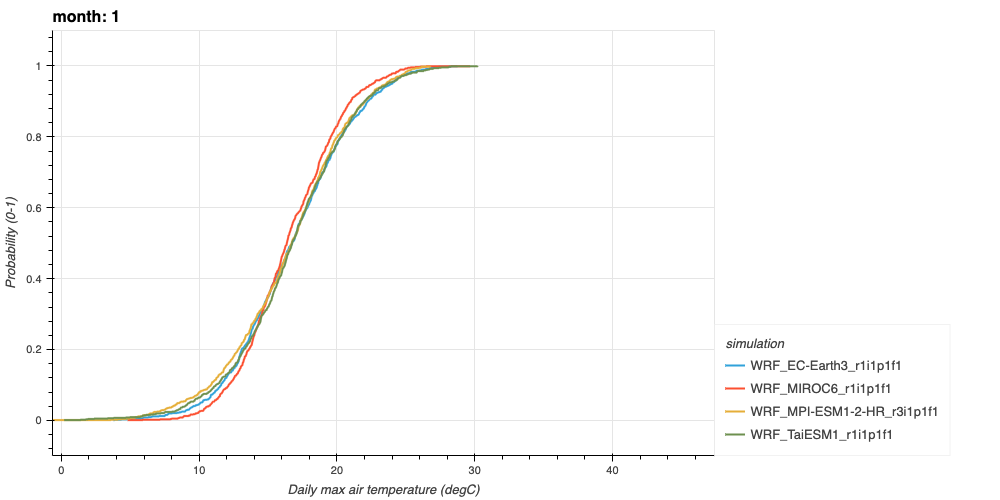
Figure 1. An example of the long-term climatological conditions of daily max air temperature, for use in a TMY. This CDF represents the baseline conditions of January max air temperatures in 4 bias-adjusted WRF models at Los Angeles International Airport (LAX) from 1990-2020.
Step 4: Calculate the per-year per-month distribution.
The AE then calculates the CDF for each month of each year (i.e., January 2001, January 2002, and so on). This process is repeated for all variables. At this point the AE also removes specific months from consideration if they occurred during major volcanic eruptions like Pinatubo (June 1991 to December 1994), because volcanic aerosols have a major impact on solar variables.
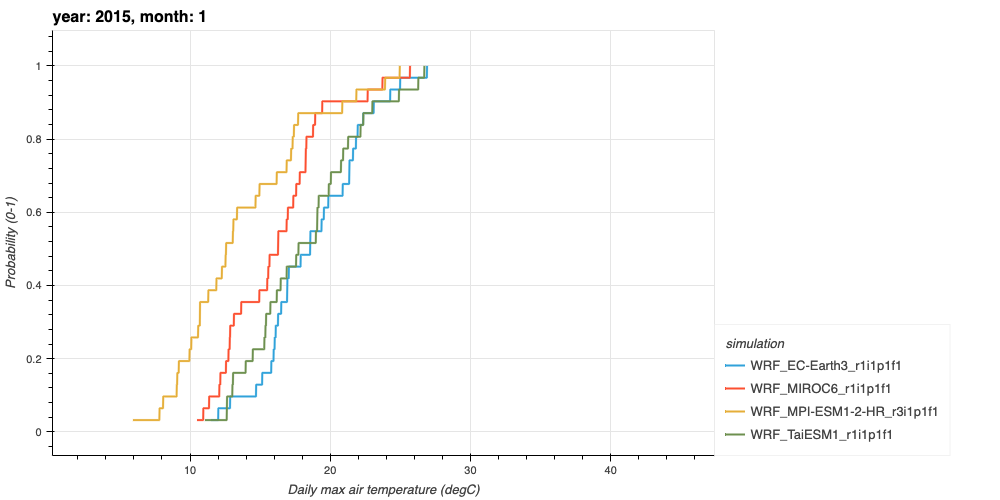
Figure 2. An example of a candidate month’s daily max air temperature, for use in a TMY. This CDF represents the January 2015 conditions of max air temperatures in 4 bias-adjusted WRF models at Los Angeles International Airport (LAX). The TMY process identifies the closest candidate month to the long-term climatological conditions to pick a “typical” month of January. For example, one would look for the closest instance of the distribution in this Figure to that of the first figure.
Step 5: Identify the month closest to climatology.
The long-term climatological distribution (Step 3) is then compared to the monthly distribution (Step 4) for each variable. The closest individual month to the climatology is determined by a F-S statistic, which describes the absolute difference between the climatological distribution and each candidate month’s distribution profile.
Step 6: Weight the input variables.
The results from the F-S statistic (Step 5) are then weighted based on the input variables. The AE uses the NREL scheme, which places higher weight on the solar variables due to their use in building and solar renewables applications:
- Mean air temperature: 2/20, or 10%
- Min air temperature: 1/20, or 5%
- Max air temperature: 1/20, or 5%
- Mean dew point temperature: 2/20, or 10%
- Min dew point temperature: 1/20, or 5%
- Max dew point temperature: 1/20, or 5%
- Mean wind speed: 1/20, or 5%
- Max wind speed: 1/20, or 5%
- Global irradiance: 5/20, or 25%
- Direct irradiance: 5/20, or 25%
Since the TMY methodology heavily weights the solar radiation input data, be aware that the final selection of “typical” months may not be typical for the non-solar radiation variables. In other words, what is selected as a typical June is based on the heavily weighted solar radiation conditions. That same month may not equally represent typical median June air temperatures.
Note: The ISO method for calculating TMYs utilizes a different weighting scheme, instead prioritizing air temperature, relative humidity, solar radiation, and wind speed.
Step 7: Select candidate month for each month of the year.
Once weighted, the AE selects the top month for each month of the year that has the lowest weighted sum, meaning that the candidate month is the closest or most “typical” to the long-term climatology for that specific month. The AE TMY method ensures that model data is kept intact, meaning that the most typical month is selected from the same model, not across models (e.g., not: January from MIROC6 and February from EC-Earth3). The end result of this process is that a TMY profile is generated for each model. This provides a great opportunity to be able to do multi-model comparisons of TMY profiles in a physically consistent space.
Step 8: Generate the TMY 8760 profile.
Once the “typical” months are selected, the AE generates the full hourly information by providing the standard meteorological information for a TMY profile. A TMY profile includes information on: air temperature, dewpoint temperature, relative humidity, global irradiance, direct irradiance, diffuse irradiance, downwelling radiation, wind speed and direction, and surface air pressure, for each of the specific months determined by Step 7 for all four models. Smoothing at the monthly interface between months is performed via curve fit to prevent discontinuities between months (Wilcox and Marion 2008). TMY profiles are provided in several formats, based on the user’s needs: .csv, .epw, and .tmy. On AE, a TMY profile for a point location takes approximately 40 minutes to generate.
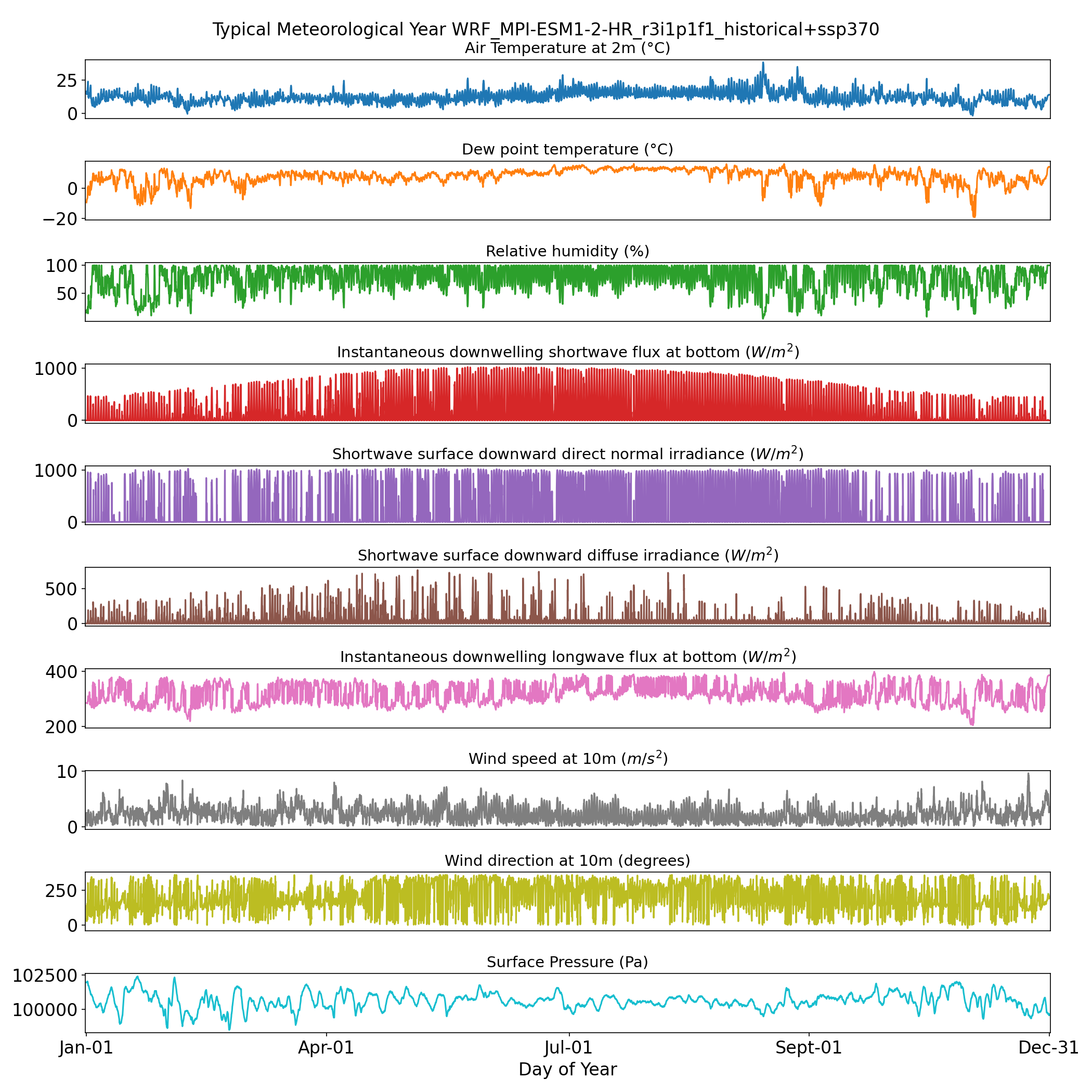
Figure 3. An example historical TMY hourly profile for Los Angeles International Airport (LAX) for the 1990-2020 period, from MPI-ESM1-2-HR.
Applications
A TMY dataset is a specific kind of annualized hourly climate profile. They represent the most typical conditions for multiple variables during a designated climatological period and include the natural diurnal and seasonal variations that occur within a 1-year period (NSRDB). Because TMYs are specifically developed for long-term planning of solar energy and to inform the design of buildings, the variables and weights that they use are therefore also specific to these applications. It is critical to note that although TMYs may reduce simulation workload associated with evaluating every year of data for different variables (Qian et al. 2023), misapplication of TMY data into planning processes can propagate misfitted assumptions about “median conditions” into risk assessments, infrastructure planning, and policy design.
Example appropriate applications of TMYs
- Average annual building energy consumption and design simulations (Wilcox and Marion 2008; NYSERDA 2020; Sobie and Curry 2025), especially heating and cooling loads
- Production estimates and performance comparisons of different energy systems types, especially solar systems (Wilcox and Marion 2008; Crawley and Lawrie 2015; Chowdhury 2023; Li et al. 2023; Zeng et al. 2025)
- Energy asset and equipment sizing (NYSERDA 2020)
Example inappropriate applications of TMY
- Extreme event analysis, including high-impact hazards such as extreme heat, cold spells, wildfire (Wilcox and Marion 2008; Peltier et al. 2024; NYSERDA 2020) and power outages (NYSERDA 2020) (see XMYs below for extreme event analysis)
- Capturing compounding and cascading events (see XMYs below for extreme event analysis)
- Historical TMYs should not be used for future building design (Li et al. 2023; Zeng et al. 2025; Laxo 2023) (see FTMYs below)
- Evaluation of actual system performance (NYSERDA 2020)
- Near-real time forecasting (Wilcox and Marion 2008])
- Custom weighting of variables; although alternative approaches may be appropriate based on specific use cases (e.g., specific building applications; Qian et al. 2023)
Common Acronyms & Shorthand for TMYs
- TMY: Typical Meteorological Year - A TMY that provides the median conditions. TMYs can be computed for historical periods of time (a Historical TMY) or a future period of time (a Future TMY). The TMYs generated on AE are model-based TMYs.
- Historical TMY - A TMY profile that provides median weather conditions for a historical period, which can be derived from historical observations or historical climate model data.
- FTMY: Future Typical Meteorological Year - A TMY that provides median weather conditions for a future period, which can only be derived from future climate model data.
- XMY: Extreme Typical Meteorological Year - A TMY that provides extreme weather conditions, either for a historical or future period, which can only be derived from model data. XMYs may also be referred to as “EMY”.
- AMY: Actual Meteorological Year - The observed historical weather conditions from a specific year, which is used as a comparison to the synthetically-generated composite TMY year.
Note: AE has previously used “average meteorological year” for single-variable 8760s, which was also referred to as “AMY”. This terminology has been removed from the AE to avoid confusion.
Future TMYs
Future TMYs (FTMYs) incorporate future climate model data into a TMY framework using the same variables and weighting scheme. Given the multi-decadal lifespan of buildings and potential changes to energy system performance under climate conditions, FMTYs enable more forward-looking assessments of expected changes in their performance than TMYs constructed using historical data (Laxo 2023; NYSERDA 2020; Chowdhury 2023; Bass and New 2020; Smith et al. 2025; Sobie and Curry 2025; Rady et al. 2025; Peltier et al. 2024).
Recommendations for FTMYs
- Carefully consider whether a global warming level or a time-based approach for calculating a FTMY, especially with regards to projected climatic change over several decades (Laxo 2023; Sobie and Curry 2025). On AE, FTMYs can be calculated using a Global Warming Level approach which ensures consistency between future climate projections and reduces uncertainties resulting from the wide range of climate sensitivity in climate models
- Select the location of interest as needed by the analysis, rather than relying on weather station locations.. Historical observation-based TMYs are historically based on weather station locations which may be far away from urban areas and not accurately reflect the actual highly localized microclimatic environment, especially for phenomena such as the urban heat island effect (Li et al. 2023). On AE, TMYs and FTMYs can be calculated at any location within the WECC area, given latitude and longitude coordinates.
Extreme TMYs
Extreme TMYs (XMYs) are fairly new extensions of TMYs, which has been enabled by the increasing use of climate model simulations to statistically assess and characterize extremes. There is currently no one recommended or accepted methodology for calculating an XMY. However, the general intent of an XMY is to select more extreme months (e.g., Crawley and Lawrie 2015; Crawley and Lawrie 2019; Bass and New 2020; Zeng et al. 2025) instead of the median conditions represented in a TMY, and to use a large set of climate model simulations to do so. Energy sector practitioners are interested in XMYs and extreme 8760s in order to better understand how a changing climate will affect building performance and other similar applications. This will require guidance, updated standards, and trust in the data to do so (Peltier et al. 2024). AE intends to release extreme 8760s in 2026, alongside associated guidance and referenceable material.
Next steps: working with TMY files
After generating model-based TMY files, users may ask what steps to take next. When generating TMY files on the AE, one TMY file per model is returned. No further aggregation or downsampling is performed, as the appropriate approach depends on the user’s specific application and need for the TMY information. The following guidance is provided to support next steps in using these data.
When to evaluate the range of results
When the application requires an understanding of the range of future, or even extreme, options using a TMY data format, it is first recommended to evaluate whether a TMY, FTMY, or XMY is the most appropriate dataset to use. If a TMY or FTMY is needed, it is recommended to use a GWL-based TMY or FTMY, instead of a time-based climatological reference period. The GWL method reduces uncertainties between models and alleviates the hot model problem, so that the user can more directly compare model-based FTMYs at a specific planning horizon. From there, evaluate the differences between models and how they can inform the analysis. At this stage, users may elect to aggregate the FTMYs and conduct an uncertainty analysis across the results.
When to aggregate results
If an application requires a single TMY, users may elect to aggregate results. It is recommended to evaluate TMYs from all of the available models to understand where each falls in the spread of conditions as well as the need for physically consistent results.
- Multi-model median: A TMY itself is designed to capture median conditions, therefore calculating a multi-model median may be the most appropriate aggregation approach. A multi-model median is recommended over a multi-model mean, because the mean is sensitive to outliers (extreme values) whereas a median is not, even with a “typical” TMY. Different considerations should be made for XMYs (forthcoming).
- Multi-model range: Consider calculating the multi-model difference for each hour between the “max” and “min” model spread of conditions as a measure of uncertainty in addition to the multi-model median.
When to select a single model
If an aggregated TMY (e.g., multi-model median) is not appropriate or desired (e.g. when it is necessary to retain a single model’s synthetic record rather than aggregate), users may elect to select a TMY from a single model. It is recommended that users first evaluate all of the available models to understand where each falls in the spread of “median” conditions. Additionally, it is strongly recommended that users document which model was selected and why.
- Selecting the median model: A TMY itself is designed to capture median conditions, therefore the median model may be the most appropriate selection.
- Selecting any model: If the range between models is very small, or not critical for the application or location, any model can serve as a representation of the ensemble.
When to weight results
Weighting may be appropriate for the user’s application if the user needs to consider multiple locations in their analysis using TMY data. For example, weighting TMY profiles for a gridded area assessment is a common application, especially in the Building Standards space. Weighting options may include:
- Population weighting: for building capacity, or in comparison across different locations
- Location-based weighting: if your area of interest falls between several different weather stations
- Load weighting: for generation and demand forecasting capacity across a service territory
- Building design weighting: for comparison amongst different building types (e.g., commercial vs. residential)